
If you have ever used a language model through a playground or an API, you may have been asked to choose some input parameters. For many of us, the meaning of these parameters (and the right way to use them) is less than totally clear.

This article will teach you how to use these parameters to control hallucinations, inject creativity into your model’s outputs, and make other fine-grained adjustments to optimize behavior. Much like prompt engineering, input parameter tuning can get your model running at 110%.
By the end of this article, you’ll be an expert on five essential input parameters — temperature, top-p, top-k, frequency penalty, and presence penalty. You’ll also learn how each of these parameters helps us navigate the quality-diversity tradeoff.
So, grab a coffee, and let’s get started!
Background
Before we start, we will need to go over some background information about how these models work. Let’s start our deep dive by reviewing the fundamentals.
To read a document, a language model breaks it down into a sequence of tokens. A token is just a small chunk of text that the model can easily understand: It could be a word, a syllable, or a character. For example, “Megaputer is great!” could be broken down into five tokens: [“Mega”, “puter ”, “is ”, “ great”, “!”]. This is done by the tokenizer.
Most language models we are familiar with operate by repeatedly generating the next token in a sequence. Each time the model wants to generate another token, it re-reads the entire sequence and then predicts the token that should come next. This strategy is known as autoregressive generation.
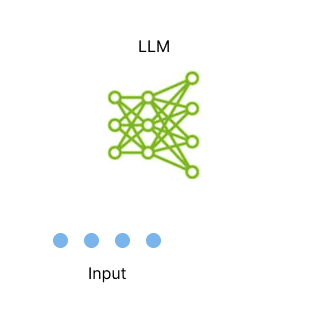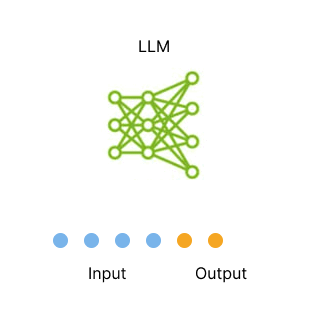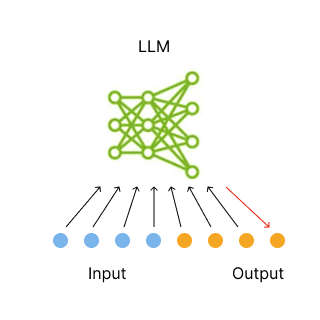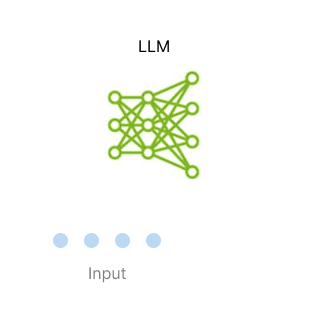
This explains why ChatGPT prints the words out one at a time: It is streaming the words to you as it writes them.
To generate a token, a language model assigns a likelihood score to each token in its vocabulary. A token gets a high likelihood score if it is a good continuation of the text and a low likelihood score if it is a poor continuation of the text, as assessed by the model. The sum of the likelihood scores over all tokens in the model’s vocabulary is always exactly equal to one.
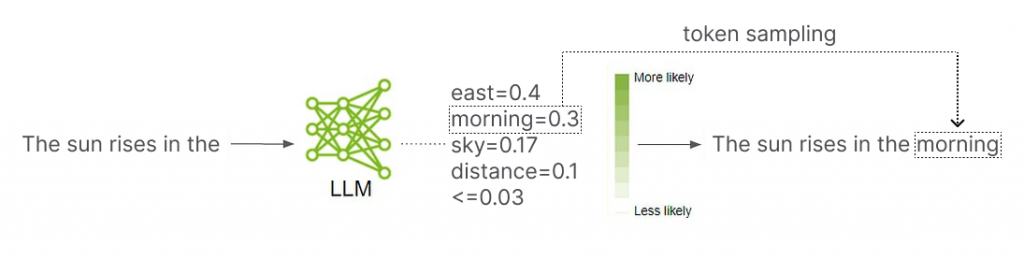
After the likelihood scores are assigned, a token sampling scheme is used to pick the next token in the sequence. The token sampling scheme may incorporate some randomness so that the language model does not answer the same question in the same way every time. This randomness can be a nice feature in chatbots, as well as in some other applications.
TLDR: Language models break down text into chunks, predict the next chunk in the sequence, and mix in some randomness. Repeat as needed to generate output.
Quality, Diversity, and Temperature
But why would we ever want to pick the second-best token, the third-best token, or any other token besides the best, for that matter? Wouldn’t we want to pick the best continuation (the one with the highest likelihood score) every time? Often, we do. But if we picked the best answer every time, we would get the same answer every time. If we want a diverse range of answers, we may have to give up some quality to get it. This sacrifice of quality for diversity is called the quality-diversity tradeoff.
With this in mind, temperature tells the machine how to navigate the quality-diversity tradeoff. Low temperatures mean more quality, while high temperatures mean more diversity. When the temperature is set to zero, the model always samples the token with the highest likelihood score, resulting in zero diversity between queries, but ensuring that we always pick the highest quality continuation as assessed by the model.
Most commonly, we will want to set the temperature to zero for text analytics tasks. This is because, in text analytics, there is often a single “right” answer that we want to get every time. At temperature zero, we have the best chance of arriving at this answer in one shot. I like to set the temperature to zero for entity extraction, fact extraction, sentiment analysis, and most other things that I get up to in my job as an analyst. As a rule, you should always choose temperature zero for any prompt that you will only pass to the model once, as this is most likely to get you a good answer.
At higher temperatures, we see more garbage and hallucinations, less coherence, and lower quality of responses on average, but also more creative and diverse responses. We use temperatures higher than zero when we want to pass the same prompt to the model many times and get many creative responses. We recommend that you should only use non-zero temperatures when you want to ask the same question twice and get two different answers.
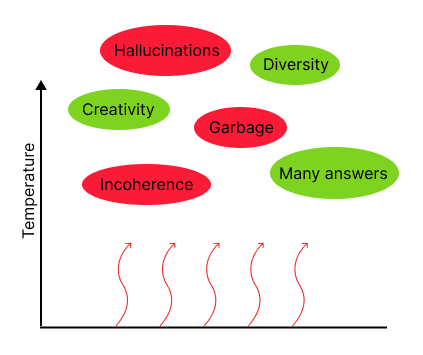
And why would we ever want two different answers to the same prompt? In some cases, having many answers to one prompt can be very useful. For example, there is a technique in which we generate many answers to a prompt and keep only the best one, which often produces better answers than a single query at temperature zero. Another use case is synthetic data generation: We want many synthetic data points, not just one. We may discuss these use cases (and others) in later articles, but more often than not, we need only one answer. When in doubt, choose temperature zero!
It is important to note that while temperature zero should in theory produce the same answer every time, this may not be true in practice! This is because the GPUs the model is running on can be prone to small miscalculations, such as rounding errors. These errors introduce a low level of randomness into the calculations, even at temperature zero. Since changing one token in a text can significantly alter its meaning, a single error may cause a cascade of different token choices later in the text, resulting in an almost totally different output. But rest assured that this usually has a negligible impact on quality. We only mention it so that you’re not surprised when you get some randomness at temperatures zero.
There are more ways to navigate the quality-diversity tradeoff than temperature alone. In the next section, we will discuss some modifications to the temperature sampling technique. But if you are content with using temperature zero, feel free to skip it for now. You may rest soundly knowing that your choice of these parameters at temperature zero will not affect your answer.
TLDR: Temperature increases diversity but decreases quality by adding randomness to the model’s outputs.
Top-k and Top-p sampling
One common way to tweak our token-sampling formula is called top-k sampling. Top-k sampling is a lot like ordinary temperature sampling, except that the lowest likelihood tokens are excluded from being picked: Only the “top k” best choices are considered, which is where we get the name. The advantage of this method is that it stops us from picking truly bad tokens.
Let’s suppose, for example, that we are trying to make a completion for “The sun rises in the…” Then, without top-k sampling, the model considers every token in its vocabulary as a possible continuation of the sequence. Then there is some non-zero chance that it will write something ridiculous like “The sun rises in the refrigerator.” With top-k sampling, the model filters out these truly bad picks and only considers the k best options. By clipping off the long tail, we lose a little diversity, but our quality shoots way up.
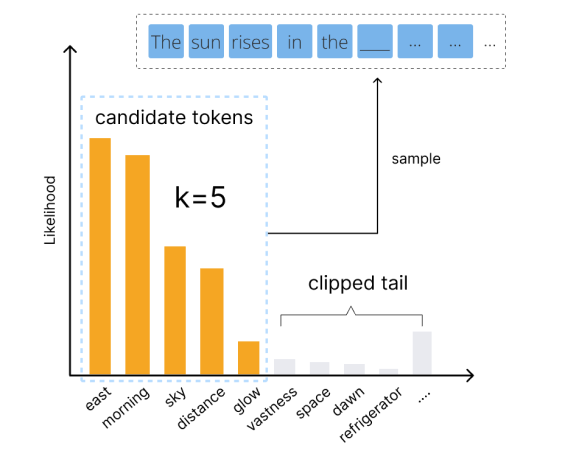
Top-k sampling is a way to have your cake and eat it too: It gets you the diversity you need at a smaller cost to quality than with temperature alone. Since this technique is so wildly effective, it has inspired many variants.
One common variant of top-k sampling is called top-p sampling, which is also known as nucleus sampling. Top-p sampling is a lot like top-k, except that it uses likelihood scores instead of token ranks to determine where it clips the tail. More specifically, it only considers those top-ranked tokens whose combined likelihood exceeds the threshold p, throwing out the rest.
The power of top-p sampling compared to top-k sampling becomes evident when there are many poor or mediocre continuations. Suppose, for example, that there are only a handful of good picks for the next token, and there are dozens that just vaguely make sense. If we were using top-k sampling with k=25, we would be considering many poor continuations. In contrast, if we used top-p sampling to filter out the bottom 10% of the probability distribution, we might only consider those good tokens while filtering out the rest.
In practice, top-p sampling tends to give better results compared to top-k sampling. By focusing on the cumulative likelihood, it adapts to the context of the input and provides a more flexible cut-off. So, in conclusion, top-p and top-k sampling can both be used at non-zero temperatures to capture diversity at a lower quality cost, but top-p sampling usually does it better.
Tip: For both of these settings, lower value = more filtering. At zero, they will filter out all but the top-ranked token, which has the same effect as setting the temperature to zero. So please use these parameters, but be aware that setting them too low will give up all of your diversity.
TLDR: Top-k and top-p increase quality at only a small cost to diversity. They achieve this by removing the worst token choices before random sampling.
Frequency and Presence Penalties
We have just two more parameters to discuss before we start to wrap things up: The frequency and presence penalties. These parameters are — big surprise— yet another way to navigate the quality-diversity tradeoff. But while the temperature parameter achieves diversity by adding randomness to the token sampling procedure, the frequency and presence penalties add diversity by penalizing the reuse of tokens that have already occurred in the text. This makes the sampling of old and overused tokens less likely, influencing the model to make more novel token choices.
The frequency penalty adds a penalty to a token for each time it has occurred in the text. This discourages repeated use of the same tokens/words/phrases and also has the side effect of causing the model to discuss more diverse subject matter and change topics more often. On the other hand, the presence penalty is a flat penalty that is applied if a token has already occurred in the text. This causes the model to introduce more new tokens/words/phrases, which causes it to discuss more diverse subject matter and change topics more often without significantly discouraging the repetition of frequently used words.
Much like temperature, the frequency and presence penalties lead us away from the “best” possible answer and toward a more creative one. But instead of doing this with randomness, they add targeted penalties that are carefully calculated to inject diversity into the answer. On some of those rare tasks requiring a non-zero temperature (when you require many answers to the same prompt), you might also consider adding a small frequency or presence penalty to the mix to boost creativity. But for prompts having just one right answer that you want to find in just one try, your odds of success are highest when you set all of these parameters to zero.
As a rule, when there is one right answer, and you are asking just one time, you should set the frequency and presence penalties to zero. But what if there are many right answers, such as in text summarization? In this case, you have a little discretion. If you find a model’s outputs boring, uncreative, repetitive, or limited in scope, judicious application of the frequency or presence penalties could be a good way to spice things up. But our final suggestion for these parameters is the same as for temperature: When in doubt, choose zero!
We should note that while temperature and frequency/presence penalties both add diversity to the model’s responses, the kind of diversity that they add is not the same. The frequency/presence penalties increase the diversity within a single response. This means that a response will have more distinct words, phrases, topics, and subject matters than it would have without these penalties. But when you pass the same prompt twice, you are not more likely to get two different answers. This is in contrast with temperature, which increases diversity between responses: At higher temperatures, you will get a more diverse range of answers when passing the same prompt to the model many times.
I like to refer to this distinction as within-response diversity vs. between-response diversity. The temperature parameter adds both within-response AND between-response diversity, while the frequency/presence penalties add only within-response diversity. So, when we need diversity, our choice of parameters should depend on the kind of diversity we need.
TLDR: The frequency and presence penalties increase the diversity of subject matters discussed by a model and make it change topics more often. The frequency penalty also increases the diversity of word choice by reducing the repetition of words and phrases.
The Parameter-Tuning Cheat Sheet
This section is intended as a practical guide for choosing your model’s input parameters. We first provide some hard-and-fast rules for deciding which values to set to zero. Then, we give some tips to help you find the right values for your non-zero parameters.
I strongly encourage you to use this cheat sheet when choosing your input parameters. Go ahead and bookmark this page now so you don’t lose it!
Rules for setting parameters to zero:
Temperature:
- For a single answer per prompt: Zero.
- For many answers per prompt: Non-zero.
Frequency and Presence Penalties:
- When there is one correct answer: Zero.
- When there are many correct answers: Optional.
Top-p/Top-k:
- With zero temperature: The output is not affected.
- With non-zero temperature: Non-zero.
If your language model has additional parameters not listed here, leave them at their default values.
Tips for tuning the non-zero parameters:
Make a list of those parameters that should have non-zero values, and then go to a playground and fiddle around with some test prompts to see what works. But if the rules above say to leave a parameter at zero, leave it at zero!
Tuning temperature/top-p/top-k:
- For more diversity/randomness, increase the temperature.
- With non-zero temperatures, start with a top-p around 0.95 (or top-k around 250) and lower it as needed.
Troubleshooting:
- If there is too much nonsense, garbage, or hallucination, decrease temperature and/or decrease top-p/top-k.
- If the temperature is high and diversity is low, increase top-p/top-k.
Tip: While some interfaces allow you to use top-p and top-k at the same time, we prefer to keep things simple by choosing one or the other. Top-k is easier to use and understand, but top-p is often more effective.
Tuning frequency penalty and presence penalty:
- For more diverse topics and subject matters, increase the presence penalty.
- For more diverse and less repetitive language, increase the frequency penalty.
Troubleshooting:
- If the outputs seem scattered and change topics too quickly, decrease the presence penalty.
- If there are too many new and unusual words, or if the presence penalty is set to zero and you still get too many topic changes, decrease the frequency penalty.
TLDR: You can use this section as a cheat sheet for tuning language models. You are definitely going to forget these rules, so bookmark this page and use it later as a reference.
Wrapping up
There is no limit to the possible token-sampling strategies out there. Other notable strategies include beam search and adaptive sampling. However, the ones we’ve discussed here — temperature, top-k, top-p, frequency penalty, and presence penalty — are the most commonly used parameters. These are the parameters that you can expect to find in models like Claude, Llama, and the GPT series. In this article, we have shown that all of these parameters are really just here to help us navigate the quality-diversity tradeoff.
Before we go, there is one last input parameter to mention: maximum token length. The maximum token length is just the cutoff where the model stops printing its answer, even if it is not finished responding. After this complex discussion, we hope this one is self-explanatory. ?
As we move further in this series, we’ll do more deep dives into advanced topics. Future articles will discuss prompt engineering, choosing the right language model for your use case, and more! Stay tuned, and keep exploring the vast horizons of language models with Megaputer Intelligence.
TLDR: When in doubt, set the temperature, frequency penalty, and presence penalty to zero. If that doesn’t work for you, reference the cheat sheet above.