Today is the big day. Maybe your product just launched, your new feature went live, or the results of the survey are in. Thousands of comments, reviews, support tickets (or whatever other data you can imagine) are flooding your system, and your team desperately needs to make sense of it all. But first, someone has to organize all this feedback into a meaningful form.
Using traditional methods, a team might need 3-4 weeks to taxonomize the data, assuming they can work on the problem full-time. By then, the crucial issues will have festered, opportunities will have passed, and the critical window for rapid response will have already slammed shut. You can also use a pre-built taxonomy, but this will capture only the categories that you were able to anticipate in advance.
An AI-powered Just-in-Time Taxonomy system solves this problem. Instead of spending weeks manually creating categories or trying to force your data into prechosen boxes where it does not really fit, the Just-in-Time Taxonomy system employs a pair of collaborating AI agents to analyze your data and build a custom taxonomy in under an hour. This gives you a taxonomy that was built from your own data on day one.
But how does this work? And when does it make sense to use this approach instead of traditional methods?
How it works: A two-agent system
The Just-in-Time taxonomy system uses two specialized AI agents that work in tandem to analyze your data.
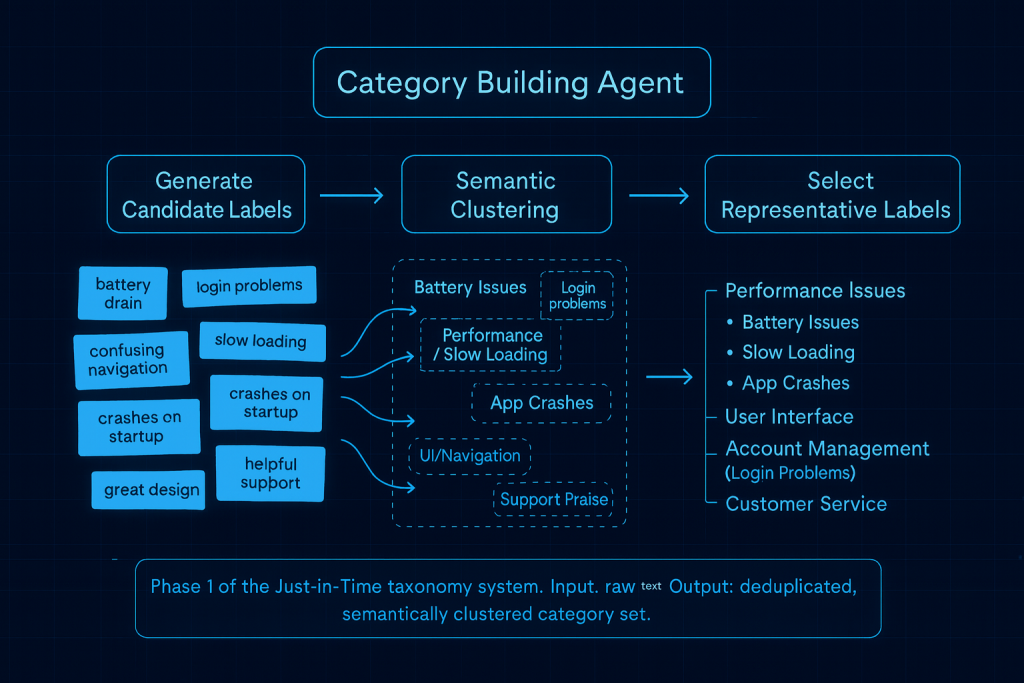
The Category Building Agent (aka Category Builder) is responsible for discovering what categories actually exist in your data. It works through a three-stage process: first, it reads through your content and generates candidate labels for the themes it finds. For example, if your data was customer feedback about a mobile app, the agent might identify candidate labels like “battery drain,” “login problems,” “slow loading,” “confusing navigation,” “crashes on startup,” “great design,” “helpful support,” and dozens of others as it processes each piece of feedback.