
In the past few years, more and more organizations have started relying solely on Machine Learning (also called Artificial Intelligence or AI) for addressing Text Analytics tasks. The reasons are that this approach is faster, suitable for large volumes of data, and more adaptable to new contexts, as it does not require hard-coded rules. However, AI / Machine Learning algorithms are only as good as the data they are trained on.
A good training dataset usually requires expert knowledge for pre-categorizing or “tagging” the input features for the model, which is often performed manually. These training datasets are also known as “gold standard data” and are not easy to obtain: it requires time and many trained people to produce an accurately tagged dataset, which can be very expensive. This is why many machine learning solutions use a statistical approach for identifying and categorizing input features for training, often resulting in solutions with high recall but low precision.

What about the Rule-Based approach?
Even though it has been abandoned lately in favor of machine learning solutions, it offers certain advantages over the latter method. Since the rules are created by humans, the results are consistent and more accurate. It is also easier to understand the logic behind the machine’s decisions and improve a model, instead of trying to comprehend a “black box”, which is the case with most machine learning algorithms. But the main issue with this approach is that the rules are hard-coded and are limited to the existing context, making it hard to adapt to new context; this results in higher precision, but lower recall.

Ideally, we would like to get the best of both worlds: the aspects of a Rule-Based approach that result in high precision and the aspects from Machine Learning that result in high recall. So how can we combine them efficiently?
Making Gold from Rules
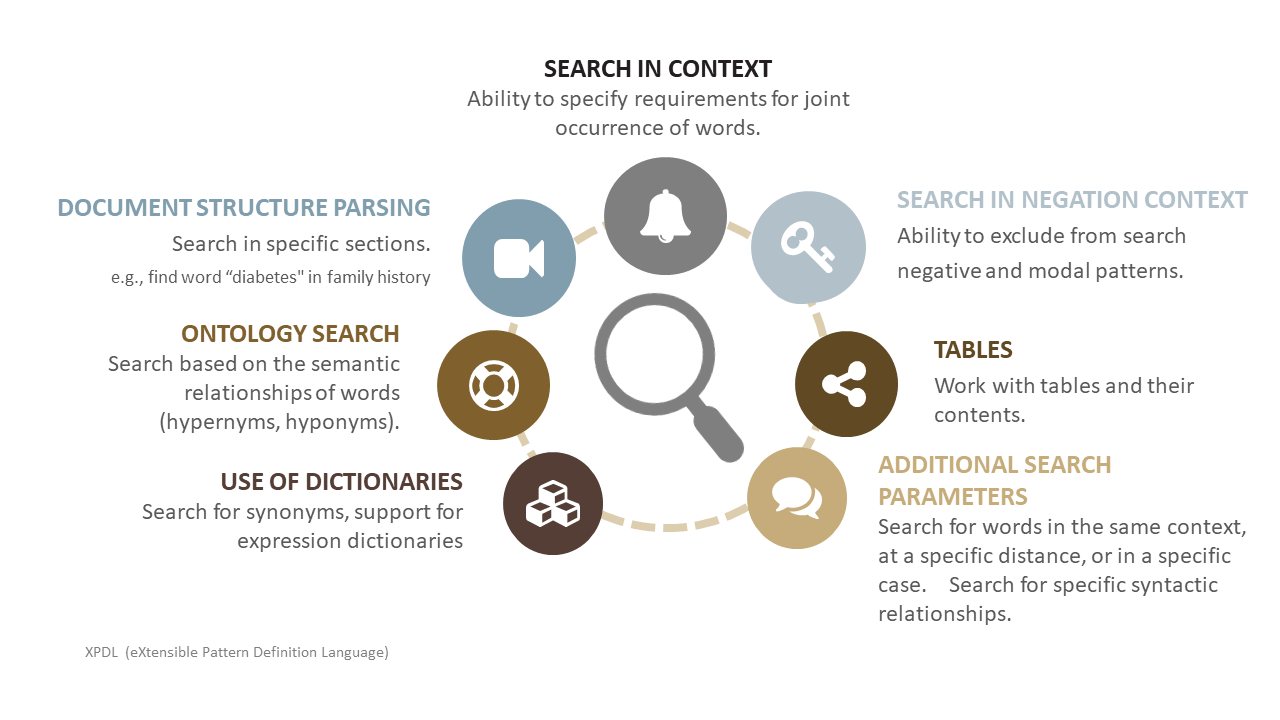
The solution proposed by Megaputer involves using a rule-based approach to generate training datasets. This approach works by utilizing a highly accurate query language that removes the need for manual tagging, while still achieving similar results. PolyAnalyst’s Pattern Definition Language (PDL) navigates and leverages the linguistic properties of text; it allows an expert to teach a machine how to identify and categorize important features that are necessary for generating training datasets with “gold standard” quality.
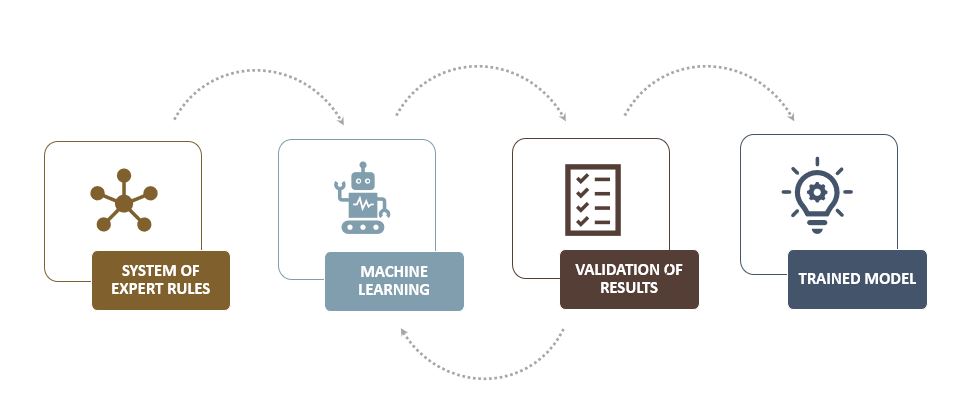
Once the machine is given expert guidance with rules and has generated the pre-categorized training data, it can expand its knowledge to additional or new contexts through Machine Learning.
A Step Forward
Thus, with a combined approach, we achieve both the high precision that Rule-Based approaches bestow on created training datasets, along with the high recall that is achieved through Machine Learning in different contexts. If you are interested in automating the generation of accurate training data to improve the results of your Machine Learning models, contact us and learn about the tools we have available.
