We are pleased to announce that PolyAnalyst now supports modeling data using convolutional neural networks. A convolutional neural network, also known as a ConvNet or CNN, is a particular kind of neural network. Understanding what a ConvNet does is simply a matter of understanding the general concept of a neural network, and then focusing on the distinct characteristics of the convolutional adjective.
We are pleased to announce that PolyAnalyst now supports modeling data using convolutional neural networks. A convolutional neural network, also known as a ConvNet or CNN, is a particular kind of neural network. Understanding what a ConvNet does is simply a matter of understanding the general concept of a neural network, and then focusing on the distinct characteristics of the convolutional adjective.
Neural networks are one of the most popular methods for solving machine learning problems such as:
- Classification – assigning data points to a hierarchy of classes, also known as labels. For example, determining who you might vote for based on where you live and your income, and then labeling you as a particular kind of voter.
- Regression – measuring how a numerical value changes based on the values of other inputs, typically for predicting a future value. For example, determining how likely it is to rain tomorrow, or how likely you are to be a repeat customer.
- Clustering – measuring the similarity of data points and attempting to group them. For example, identifying typical consumer markets based on purchasing behavior.
Convolutional networks are not that different from conventional neural networks. What sets ConvNets apart is their ability to process signal data, such as the pixels of an image, with remarkable efficiency. ConvNets are particularly well suited to finding patterns in noisy data, and tend to be more scalable than other neural network algorithms.
A brief history
Neural networks are certainly not new. A quick search will yield academic papers dating back to the 1940s. However, the convolutional flavor is newer, and has in recent years surged in popularity due to a renewed focus on deep learning.
Historically, ConvNets were used to process image data in an academic field known as computer vision1. ConvNets are notable for how well they lend themselves to the task of recognizing features of images, such as people’s faces, or the continually-updated external view of the surrounding environment in a self-driving car. ConvNets are also useful when processing natural language (unstructured data), and for optical character recognition (OCR).
Applications of convolutional networks
- Facebook uses convolutional neural networks to assist in automatically choosing how to tag Facebook posts.
- Google uses convolutional neural networks to assist in providing accurate search results for Google Images.
- Amazon uses convolutional neural networks to assist in recommending products to customers (cross-selling).
- Pinterest uses convolutional neural networks to assist in personalizing your home feed.
What are the advantages of convolutional neural networks?
CNNs consist of convolutional layers, which we will touch on in more detail in a moment. CNNs allow you to extract features and build a multi-layered hierarchical structure from them. In this structure, features at a higher level are derived from features at a lower level.
Convolutional layers have a smaller number of weights than fully connected layers. This increases the efficiency of training multilayer networks.
While this approach is suitable for pattern recognition tasks, it can also be applied to numerical data.
What is convolution?
Convolutional neural networks are so named because of a data processing step known as convolution. A thorough mathematical treatise on what is convolution is outside the scope of this brief article. It is sufficient to emphasize that convolution is good at extracting features from data, and more so in its aggregation and filtering of those features, so that the number of features is reduced (a.k.a. pooling). This built in feature reduction is what makes such networks so adept at analyzing feature-rich data.
What is feature reduction?
Let’s take a step back from the technical jargon. We are going to aim for intuition in our explanation.
 Feature reduction is like drawing a sketch. Imagine laying a thin piece of paper over an image, so that in a certain light, only some of the features of the image bleed through the paper. Take a pen and outline some of the lines. Then, discard the original image, and examine your sketch. The drawing contains substantially less information about the image. The original color is gone. Only some lines remain. In academia, this might be known as the application of an edge detection algorithm. Each line you have drawn is a recognized edge. As easy as it was for you, getting a computer to do this is not the easiest feat.
Feature reduction is like drawing a sketch. Imagine laying a thin piece of paper over an image, so that in a certain light, only some of the features of the image bleed through the paper. Take a pen and outline some of the lines. Then, discard the original image, and examine your sketch. The drawing contains substantially less information about the image. The original color is gone. Only some lines remain. In academia, this might be known as the application of an edge detection algorithm. Each line you have drawn is a recognized edge. As easy as it was for you, getting a computer to do this is not the easiest feat.
One of the notable characteristics of convolutional neural networks is that this edge detection step can be baked into the modeling step itself. In other approaches to machine learning, the steps of preparing the data for analysis are typically separated from the learning step. Here, a part or all of the cleaning step is merged with the learning step.
The first layers of the network serve to abstract away some of the features of the input data, and the later layers then continue processing these abstracted features as a substitute for the original. Because real world data may have thousands of useful features that could serve as decision-making criteria, it would ordinarily be cost-prohibitive to efficiently model the original data. This step of reducing the number of features via convolution and pooling in a way that increases modeling efficiency is why convolutional neural networks are so attractive.
We should point out again that this is a simplification. Real networks may involve multiple layers of feature extraction, and multiple layers of pooling. Feature refinement is an iterative process. Each time the network examines the data in its training phase, there is an opportunity to make adjustments.
Juggling the criteria for decision-making
There are trade-offs in reducing features. If the algorithm excises too many of the original features, the result is decreased fidelity.

If you recall the childhood game of Telephone, where children sit in a circle and starting with one child pass a whispered message from ear to ear, the final message is often hilariously different than the original. Each repeated utterance of the original message involves a loss of information. At some point the loss accumulates and the message changes.
One of the benefits of coupling the feature extraction step with the later layers is that the network can reconfigure itself as it memorizes new patterns. For example, if the network is doing a bad job of predicting a value, as measured by a high error rate, then the network can perform additional training that starts to consider additional features, or consider the same features in greater detail, or stop considering certain features, or view things from a different angle.
For solving the task of feature extraction, the addition of more data points to consider is not always a good thing. As more features get introduced, this can greatly increase learning time, and sometimes lead to a loss in accuracy due to an overabundance of features, similar to the difficulty of picking a person out of a crowd as the crowd size increases.
Step back and think about how good your ears are at filtering out noise from a crowded room of people to listen to one person speaking, or how adept your eyes are at filtering out information from your peripheral vision. The problem for machine learning is that machines see and hear all data indiscriminately. Machines do not come with this innate human ability to ignore objects in your visual periphery, or tune out annoying sounds and static. Machines struggle to distinguish between signal and noise.
This balancing of what data to consider and what to ignore is a juggling act. It requires some finesse. Perhaps even some subjectivity. Convolutional neural networks offer several dials to turn to achieve that. The networks mentioned in the earlier examples are highly refined.
Learning from mistakes: how neural networks evolve to make better predictions
Neural network algorithms are especially susceptible to a modeling problem of settling on a false minimum in the error calculation.
 Imagine climbing halfway up Mt. Everest and then claiming you reached the summit simply because you could not see the top of the mountain from your vantage point.
Imagine climbing halfway up Mt. Everest and then claiming you reached the summit simply because you could not see the top of the mountain from your vantage point.
Neural networks learn by minimizing error. This is similar to classical behavioral conditioning, like Pavlov’s dogs responding to the sound of a bell. A network will produce a guess, a prediction, of what a value should be, then measure the error, and then get rewarded or punished. If it gets zapped for picking a bad value, it measures how far off it was from the correct value, and then rewires its neurons so as to produce a guess that is hopefully closer to the desired value. Enough zaps, and its answer becomes more accurate (assuming that the data at least exhibits some semblance of a pattern).
However, networks are prone to settling on what a network thinks is the most accurate guess when in fact it is not. The algorithm cannot know in any given training iteration that it is finally accounted for all decision-making criteria. Instead, if the algorithm sees that after several attempts to tweak its criteria it fails to produce appreciable impact on reducing error, it gives up. It is often the case it has only climbed part of the way up or down the mountain.
The point is that no algorithm is a silver bullet. There is no one-size-fits-all machine learning approach. Be open to experimenting with other modeling approaches such as decision trees or regression.
For the most part, the other steps of any ConvNet algorithm are highly similar to a traditional neural network, so we will not be going into much more detail.
PolyAnalyst’s new Convolutional Neural Network node
PolyAnalyst recently introduced dedicated functionality for training a convolutional neural network model. The new node provides several options to configure. While many software packages that provide similar functionality tend to require an analyst to explicitly configure the network’s structure, PolyAnalyst’s implementation enables automatic structure building. In particular, PolyAnalyst’s implementation can filter and normalize the data, form a validation sample to control overfitting, train the network with the selected architecture, split the sample into training and testing batches, and ultimately select the best model.
An example of using the Convolutional Neural Network within PolyAnalyst
Speaking to readers familiar with PolyAnalyst, you can use the new node just like you would use any of PolyAnalyst’s many other modeling nodes such as classification and regression.
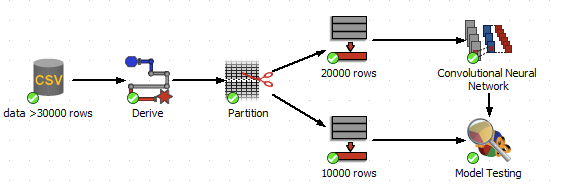
It is important to prepare the data prior to training. Once the data is in a suitable form, you will need to specify the dependent variable and the independent variables. In the following data analysis scenario, we see the input data split into a training subset and a testing subset. The model is trained on the training subset, and then tested against the testing subset.
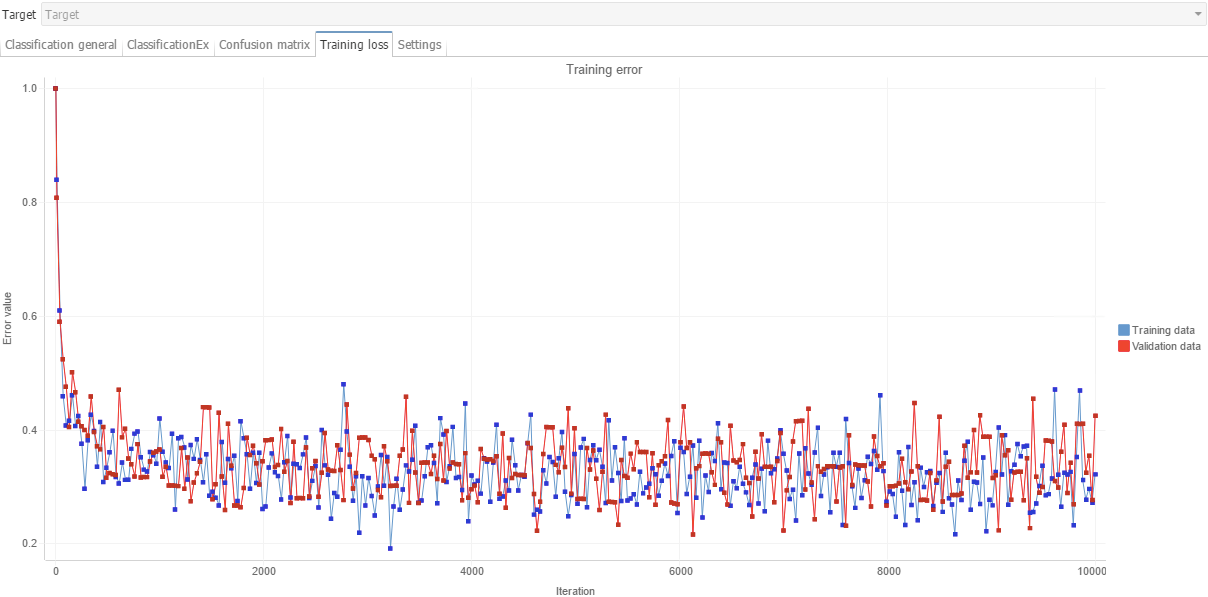
The following screenshot communicates a portion of the report that enables you to assess how well the model performed. Here, you can see how the model learned patterns in the data in an iterative fashion. This particular chart shows how the prediction error, that is what the model thinks the predicted value should be compared to what it actually is, decreases over time (with increasing number of training epochs) as the model observes more patterns and performs retraining procedures.