
As we have discussed previously, machine learning approaches to modeling are just that – approaches. There are many forms of models we could use with machine learning, each with different design philosophies and quirks. When setting out to use machine learning to create your own models, a question you may be asking yourself is: Which model framework do I choose? From Neural Networks, to Support Vector Machines, to Decision Trees, to Linear Regression, there are many options. While there is rarely a definitive or clear answer to this question, let’s discuss some things to consider when making this choice.
Model frameworks have a set of qualitative measures attached to them which, while difficult to directly measure, can be useful for thinking of. We will consider two qualities: capacity and complexity. Capacity is the measure of a model framework’s ability to describe data distributions; it can be thought of as potential accuracy. For example, imagine we scatter pebbles on the ground and would like to model the shape they form with two different models. One model is a rigid stick (depicted by the blue line) and the other is an elastic band (depicted by the red line).
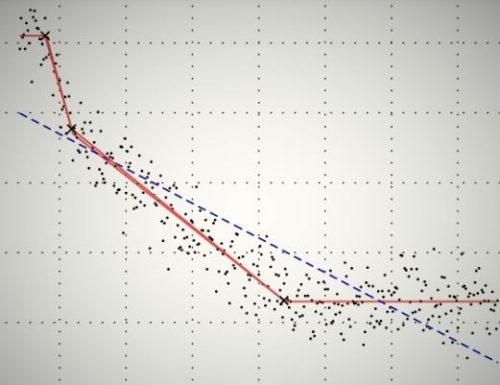
The stick has very low capacity because it can only model one shape while changing the angle that it lies on the ground. A few pebbles may fit into this model, but it is unlikely to be a good choice for many situations. The elastic band, while probably not being perfect, can twist and bend to create a host of complex curves to fit our data. This model can fit more potential data distributions and has a higher capacity.
Capacity is a very important property of models. If our model’s capacity is too low, we may never be able to adequately make predictions no matter how much training data we use or how fancy our hardware is. Models with high capacity include Neural Networks and Support Vector Machines (SVMs), and this is why they have been so popular.
However, capacity is not the only property to consider. Another quality is complexity, which can also be thought of as interpretability or how easy it is for a human to understand. In our previous example, the stick had low complexity (or high interpretability). It can be described and understood well by humans, and it is highly generalizable. Low complexity models include Linear Regression and Decision Trees. Conversely, the many curves created by the elastic band are very complex and difficult for humans to describe. SVMs and Neural Networks would, therefore, be considered high complexity models.
This relationship between complexity and capacity that we saw in the above example is generally true for all of our models. By increasing our capacity, we often must incur the cost of increased complexity. This is part of the analysis you must consider when choosing a model. Do you need to be able to describe or personally understand what the model is doing? If so, going all in for the most complex but accurate model may not be desirable. This is why many hospitals and healthcare-related institutions often rely on less complex model structures like Random Forests. When taking the health of patients into account, doctors want to be able to understand what a model is doing before taking action on those results.
Resources
Thus far we have discussed the theoretical constraints of a trained model. Now we should consider more practical properties. A machine learning model requires training, which in turn requires data, processing power, and time. When selecting a machine learning model to use, we need to weigh how much of these resources we have available to invest in the model. Additionally, the quantification of the model itself is important. For example, if we plan to deploy the model on mobile technology, we should be cautious about how much storage the model itself requires. As expected, if we desire models with high capacity, we usually need to invest more resources into the model during training and storage. Let’s consider a sample of models and discuss the resources they require.

On the low-cost end of the spectrum are Naïve Bayes models. These models are generally lower in Capacity but are extremely easy to interpret and train. One of the main advantages of Naïve Bayes models is that they are exceedingly fast to train and store. Unfortunately, the model relies on the Naïve Bayes assumption which is rarely true for our data. However, if your data does not stray too far from that assumption, you can find that the model provides decent results in a cheap package.
Also relatively low-cost are Decision Trees and Random Forests. These models are interpretable and the tree structure of the models make them easy to store efficiently if you don’t have an enormous number of features. Unfortunately, we start to see an increase in the time required to train for these models.
SVMs, a popular technique, come with a large jump in resources required. Training these usually requires more data than other methods and the resulting models are bulky, almost impossible to interpret into plain English, and tricky to train in the first place because of the choice of kernel. However, SVM’s are powerful models when trained correctly, and thus they are widely used.
Possibly the most costly of the models are Neural Networks. Famed for their high capacity, these models require extensive processing and time to train and can take up a large chunk of storage to contain. But it isn’t all doom and gloom about the resources required for Neural Networks. Because of how they are trained, Neural Networks can take additional data to finetune the training at any point, meaning that we don’t need to retrain our models every time we get new data.
Which Model to Pick?
Ultimately, the answer is not obvious in every case. When choosing which machine learning model to use, we need to consider many different factors: What tradeoff do we want to make between capacity and complexity? What resources do we have available for our training? Do we want to be able to store the model in a compact manner? Do we want to be able to continually use new data without having to retrain the model entirely each time? Finally, we don’t always make the right choice. Sometimes we have to experiment with multiple structures to find one that fits our needs. If you can, train multiple models to help decide which one to devote your attention to.