
When facing a project requiring text analysis, it can be hard to know where to start. Language is a complex phenomenon. Language serves a variety of communicative purposes – sometimes more than one within a single expression.

An easy way to give a starting point to our analysis is to answer the following two questions:
- What am I looking for?
- How is this expressed in language?
This first question represents the end goal of your project. For example, are we searching for people’s opinions about a product in the reviews? Are we looking for specific people in the text, such as the claimant and the insured in insurance claims? Are we looking for reactions to specific drugs in medical records?
The second question is more challenging to answer. A single phenomenon may be expressed in different ways. It can also be expressed in a way that computers may not understand right away like humans do. For example, a named entity in an insurance claim may appear as a name (John Smith), as a pronoun (he or him), as a noun based on an attribute (the claimant) or as a reference to another entity (the red Mazda, in this case the claimant’s car). Computers are excellent at identifying structural patterns, but usually have trouble with higher-level notions such as social behavior. An expression such as “Where is your customer service, [Brand]?” is not an actual question about location, but rather implies that the customer is dissatisfied with their customer service. However, it is still possible to extract those higher-level meanings by finding their association with structural features.
In order to do that, it is necessary to understand that language has different levels, or building blocks, which are interconnected and associated with a variety of phenomena.
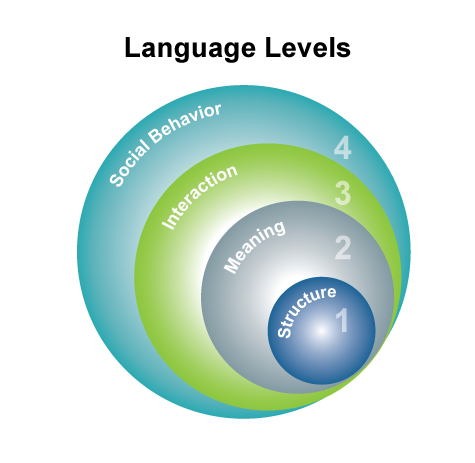
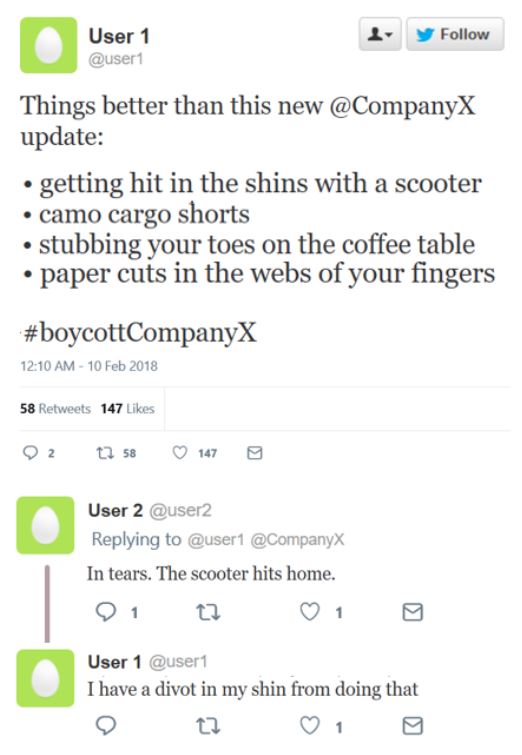
The following guide is based on Herring’s categorization of language into four levels of analysis 1; even though this categorization was created for online communication, it may also be applied to traditional text in an electronic form. Let’s take the following Twitter exchange as an example:
Structure
The first and most basic level of language is the structural level (L1). This level refers to patterns that may be objectively identified and counted for their frequency. For example, a word represents a string pattern that may be identified and counted for its frequency. Similarly, the syntactic relationship between two words is a pattern that may also be identified and counted for its frequency. In the above example, the sentence “The scooter hits home” represents the pattern: “the [noun or noun phrase] hit home” . Computers are very good at identifying such patterns, so we generally try to find structural expressions of the linguistic phenomena we are interested in.
There are several structural aspects that we take into account:
Typography. The characters or format used in a word. For example, users in online communication may substitute letters for numbers, as in gr8t (great). Moreover, a number of users use latin characters for languages with non-latin writing systems.
Orthography. The spelling of words.
Morphology. The different forms of a word (walk, walks, walking). Depending on the category (part of speech) a word belongs to, it may take different forms based on grammatical rules.
Syntax. The relationships between words.
Discourse schemata. Structural patterns at the macro level of a text, which refer to stylistic differences and organization based on the genre of the text.
Meaning
The second level of language is the meaning that we associate with character or word/phrase patterns (L2). Meaning may sometimes be subjective and may be associated with a variety of patterns. For example, we associate positive sentiment with the character patterns good or excellent or great. Similarly, not good or bad or piece of garbage represent patterns that are associated with negative sentiment. Another example is the relationship pattern in the phrase the claimant hit the insured: it has a different meaning from the phrase the insured hit the claimant. In the above Twitter example, the pattern “the [noun or noun phrase] hit home” is associated with the meaning “it resonated with me”.
Interaction
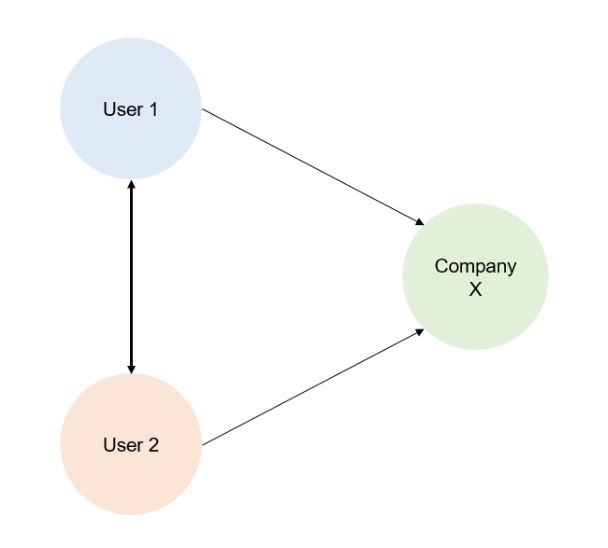
Interaction refers to the way people communicate with one another in conversations. This level of language (L3) is particularly useful for network analysis. In this case, we would look for patterns that express relationships between entities, whether the entities are people (social network analysis) or topics (topic development). In the Twitter example above, we can see that User 1 interacts with Company X. User 2 interacts with both User 1 and Company X by responding to the original tweet —and then User1 responds back only to User2 (@User2). So we have the following relationships between User1, User 2, and CompanyX that may be visualized in a network like this:
Social Behavior
Finally, the highest level of language analysis (L4) has to do with social phenomena in language: discourse styles based on social factors such as age and gender, expression of status, politeness, conflict, negotiation, etc. As humans, we are equipped with knowledge of social constructs and associate them with patterns, because we interact with people in a variety of social environments during our lives. Social phenomena in language are very context-sensitive and may be expressed in a variety of structural patterns dependent on the context. For example, the first tweet in the interaction above expresses irony, a higher level social behavior that is identified based on (social) context. The literal meaning is that the things enumerated in the tweet are better than the Company X’s update; however, our social knowledge allows us to interpret the contrast between the word “better” and the negative polarity of the enumerated things as irony. Consequently, at this high level of language, it is useful to find structural patterns capturing the context (better + words/phrases with negative polarity) that help identify the linguistic phenomenon serving the end goal of our project.
Choosing an analysis level
For automated text analysis tasks, we usually operate on the structural level. Computers are excellent at identifying patterns, but usually have trouble with higher-level phenomena that require social knowledge. Consequently, even though our text analysis project may be looking for phenomena that belong in higher language levels (meaning, interaction, social behavior), we approximate them with phenomena from the structural level because they refer to patterns that computers may identify and extract more easily and accurately.